Perfect Interactive Broadcasting Architecture
While we might sometimes talk about low-latency or interactive broadcasting in a generic way, it's important to note that there are actually two distinct types of streaming use cases that require different levels of interactivity.
- Conversational use cases where multiple participants are talking together and that conversation is being streamed to many other viewers. These viewers can potentially become speakers at some point too.
- Single stream use cases where just one person is streaming their video feed (it can be their camera, their screen, or a combination of both) to many other viewers who can interact in different ways. The most obvious way is through chat messages, but it can also include emoji reactions or even bids on an auction being streamed.
The conversational use case has specific requirements. For instance, it demands effective synchronization of multiple streams, ultra-low latency (less than 250ms) only between the users who are speaking, and an element that performs video composition of all the streams prior to forwarding it to viewers. There are a variety of approaches to implementing this, each with its own set of pros and cons, as exemplified by top products like Streamyard or the way Twitch streamers use to integrate Discord into their streams.
This post is primarily focused on the second category, which pertains to single stream use cases. What makes this particular use case compelling is:
- That single stream needs to be streamed with perfect quality if there are no network limitations. If there are network limitations, it should be streamed with the best possible quality in real-time and send the additional quality layer in the background/later to have at least the recording with the best possible quality.
- There is a single stream being sent so there is no need for synchronization of multiple sources.
- You usually don't need < 250ms latency and can prioritize providing a bit higher quality and have 1-2sec latency.
One potential requirement for these use cases is support for various endpoints such as browsers, mobile devices, smart TVs, consoles, and mobile phones. These devices have different capabilities in terms of networking, protocols, and codecs.
What would be the perfect solution in terms of quality and flexibility for this type of scenarios? (assuming infinite time to develop it and money to run it :))
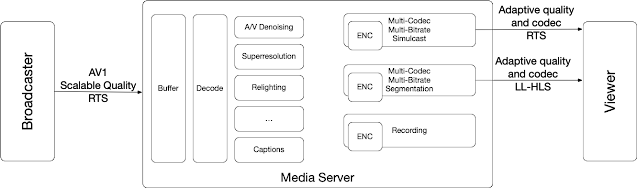
Ingestion
Use the best available codec for the endpoint, taking into account device capabilities and status (such as battery load). In many cases, this could be the AV1 video codec with a high-quality Opus audio configuration.
If possible, send a single stream with perfect quality. However, if there are network issues in the sender's uplink, send two layers of video instead. One layer should maintain the low-latency requirement, while the other can be sent in the background with as much latency as needed. This ensures that the server will end up with a layer of perfect quality eventually.
To provide low-latency delivery in the presence of packet loss in the network, use a UDP-based transport. There are different alternatives available, such as SRT, WebRTC, RUSH, and custom protocols. Let's use RTS (Real Time Streaming) as a generic name for this. If the protocol needs to be supported by browsers as well, then either WebRTC or a custom QUIC/WebTransport protocol seem like reasonable candidates. However, in the case of WebRTC, it may be harder to implement the previous idea of always having a layer with perfect quality in background, and may require some workarounds.
Processing
There are a variety of audio and video processing algorithms that are gaining popularity, such as audio and video noise removal and superresolution. However, some of these algorithms are too resource-intensive to run on many client devices.
Furthermore, the most appropriate codec on the sender side may not always be the best or supported by all receivers.
For these reasons, a server processing pipeline that includes decoding, processing, and reencoding can be highly advantageous. There are also other tasks that can be incorporated into this pipeline, such as generating captions or adding watermarks to videos.
This is the most expensive component of the system, and for some applications, it may be excessive and should be eliminated or only applied to the most important streams. If there is no Processing layer in the server then the solution becomes much simpler with the sender generating video streams in multiple qualities and the server just forwarding them without reencoding them.
Delivery
Different devices require different qualities and codecs. Additionally, some devices may be limited to HLS support, so varying protocols may be necessary.
In most cases, server side recording is also necessary.
For use cases that really require real-time functionality (probably not that many), the RTS protocol can be used. This protocol can provide different media versions, including various resolutions, bitrates, and codecs, which can be distributed using a Real Time CDN. For example, WebRTC can use SFUs infrastructure with this protocol.
For use cases that require interactivity, but not real-time functionality (most of them?), or that require compatibility with legacy devices, the LL-HLS protocol can be used. Like the RTS protocol, LL-HLS offers different media versions that can be distributed using a Traditional CDN.
And that was the proposal for a possible “perfect” broadcasting architecture for interactive use cases would look like. What do you think? As usual feedback is more than welcomed either here or in Twitter.



Salesforce admin course provides complete knowledge of CRM configuration and user management. It explains object customization and workflow automation clearly. This salesforce admin course strengthens platform management and reporting skills. Learners work on real-time business scenarios. Hands-on projects are included. Security settings are covered. It prepares job-ready administrators.
ReplyDeleteExcellent overview! A devops engineer course
ReplyDeleteis essential for mastering tools like Jenkins, Docker, Kubernetes, and cloud deployments.