Handling back-pressure in RTC services
are buffering, dropping, and controlling the sender:
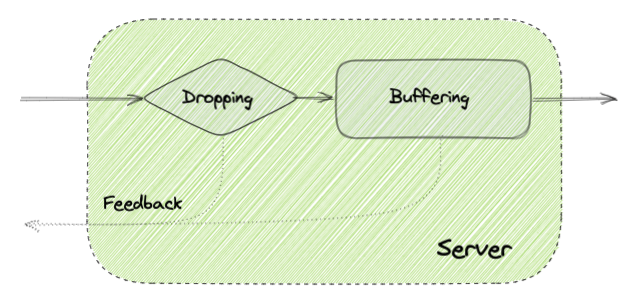
- Buffering: Messages can be queued and processed at a lower rate when needed to limit the impact of spikes or high load.
- Dropping: Messages or even connections can be dropped when it is not possible to process them fast enough. This can be problematic in case there are retries from the clients as it could create a multiplicative effect making the problem even worse, so it has to be applied carefully.
- Controlling the sender: The receiver can provide some feedback to the sender to limit the amount of traffic that it is sending to temporarily reduce the impact on the service quality.
Signaling Plane
Typically we use a websocket connection to send and receive messages related to session establishment and often also some type of presence and messaging. Given that it is a persistent TCP connection we already get some buffering for free as part of the operating system implementation that can handle some spikes in traffic. In addition to that buffering it is convenient to have a more strict buffering at connection and at room/session level to avoid a single room overloading the whole server in case of an unexpected surge in traffic in that room.
Dropping messages is not very common for the signaling plane and usually it is not an option given that we don't want to lose critical messages. But in some specific cases, it could be an option and reasonable like for example in the case of telemetry messages or sending cursor positions in a screen-sharing application.
Controlling the sender could be done explicitly (sending a feedback message to the client to suggest the client send fewer messages by adding some batching or reducing the number of videos for example) or can be done implicitly by reading slower from the buffer so that the corresponding buffer in the client-side fills up too.
Media Plane
When running media servers you get some buffering by default as part of the OS sockets implementation. The size of those buffers is something that you usually want to tune and gives you some flexibility to deal with spikes trading off delay for packet loss. For traditional use cases you probably don't want to increase it much but for high bitrate use cases where a keyframe can be really big (f.e. Stadia-like use cases) it is likely that you need to do increase those buffers. Those buffers are the first protection against small spikes but shouldn't be abused because they also increase the latency and jitter of media packets.
Dropping messages could be an option, but usually doesn't save that many resources once you have already read them also because that would trigger retransmissions (at least in case of video). So instead of dropping packets it is a better idea to disable the forwarding of specific video layers to reduce the amount of packets or in case of audio to enable dynamically dtx (discontinuous transmission) or to increase the packetization time.
Controlling the sender is probably the most common technique for the media plan. The sender can be controlled explicitly by configuring a lower sending bitrate when needed (for example using RTCP REMB messages) or can be done implicitly. In the later case, when the media servers start to get overloaded the the processing time of packets is less predictable and that introduces some jitter that as a consequence reduces the bandwidth estimation because jitter is a signal of congestion. This behaviour is something that happens automatically in most of the existing RTC solutions that include a bandwidth estimation algorithm based variability of packets delay like is the case of WebRTC.
Those were some of the techniques used in signaling and media servers that I'm aware of. What do you think? Any other ideas do you apply today to your platform? Feel free to share those here or in Twitter.



Just your smiling visitant here to express a love (:, by the way outstanding layout. allmaxbet
ReplyDeleteThe principal thing we do is go into our information base of specialists and find the ideal task author for the Empire Essay assignment. We then, at that point, affirm the request with the client and set up a record for correspondence purposes.
ReplyDeleteThanks for the kind words, I'll come back more frequently. สนใจแทงบอลคลิก
ReplyDelete