Improving Real Time Communications with Machine Learning
When we talk about the applications of Artificial Intelligence / Machine Learning (AI/ML) for Real Time Communications (RTC) we can group them in two different planes:
- Service Level: There are many features that can be added to a videoconference service, for example identification of the participants, augmented reality, emotion detection, speech transcription or audio translation. These features are usually based on image and speech recognition and language processing.
- Infrastructure Level: There are many ways to apply ML that do not provide new features but improve the quality and/or reliability of the audio/video transmission.

Service level applications are fun, but they are more for Product Managers and I like technology more, so in the next sections I will try to describe possible applications of AI/ML for Real Time Communications at Infrastructure Level organizing those ideas in five different categories.
Optimizing video quality
The first way would be to select the best possible encoding parameters for a specific video or a specific part of the frame. For example if we can detect the most important parts of the scene (maybe the talking head) and use better encoding quality (lower quantization level) for those areas. Or another example, we can detect the type of information and give preference to framerate vs quality depending if it is a high motion video or a typical conversation.
The second way could be to reduce the amount of information being sent by removing the information that can be regenerated by the receiver. As an extreme example, we all know the shape of human hair so even if you can, can you send lower quality and reconstruct the hair in the receiver? One example of this application can be seen in the RAISR demos by Google.

The same process could be also used to improve the readability or increase the detail level of objects that are too far or out of focus.
It is also possible to apply ML in the video codec implementations to optimize the processing required to encode the frames as you can see in this code included in the VP9 codebase.
Optimizing audio quality
We should be able to eliminate redundant audio data that can be regenerated in the receiver side in the same way we describe for video in the previous section. In an extreme case we would only need to send the text and the accent / speed... of the speaker and the receiver should be able to reconstruct almost the same voice based on a previous learning process.
One of the problems with audio quality is the intelligibility in noisy environments. ML algorithms can also help with this as shown by RRNoise project by Mozilla/Xiph by learning how to better differentiate and suppress noise vs voice.
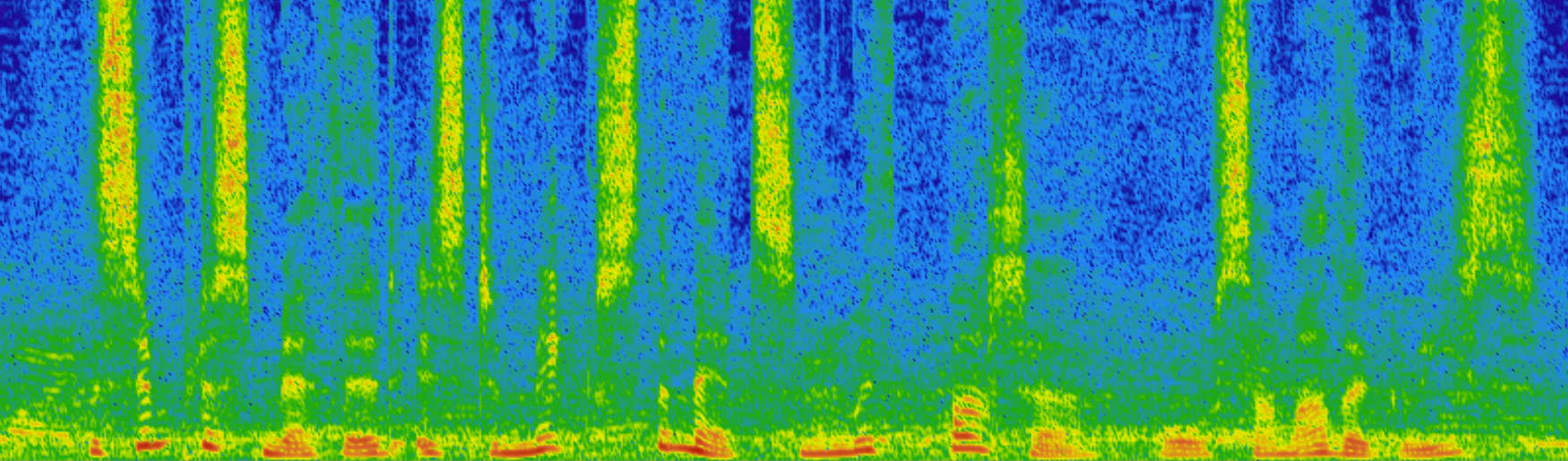
One of the problems with audio quality is the intelligibility in noisy environments. ML algorithms can also help with this as shown by RRNoise project by Mozilla/Xiph by learning how to better differentiate and suppress noise vs voice.
Tuning transmission settings
The amount of parameters involved in a RTC session is really big, it goes from codecs with tons of settings, bitrates, packetization sizes, buffers, timeouts.... Deciding which ones to use at a given time is not trivial and can even require per user/network adjusts that change dynamically. A ML based system could learn what is the best combination of those parameters for a specific user in some specific conditions.
In case of multiparty calls it is critical to include some algorithms to decide how the available bitrate is distributed for the different streams in the room. For example is it better to send 2 videos at 50kbps or disable one and send the other one at 100kbps. A ML algorithm able to make those decisions (bitrates, framerates, resolutions, codecs...) in real time based on the uplink/downlink characteristics of all the participants in the call, but also based on the type of conversation and on who is/are the active speaker/s could provide a much better quality of experience.
Resource allocation and planning
 Most of the RTC infrastructures include the concept of Media Servers. Those are the servers routing the audio and video packets between the different participants and are specially important in case of multiparty calls.
Most of the RTC infrastructures include the concept of Media Servers. Those are the servers routing the audio and video packets between the different participants and are specially important in case of multiparty calls.For these calls you can use ML algorithms to decide what is the best server to be used for a specific call based on the location of the server, the location of the participant/s and the status of the servers (basically the load and network status).
In the same way it can use for forecasting to predict load and make sure the amount of available resources is the optimum one.
Diagnostics and Monitoring
Most of the people who have been working building RTC platforms for a while has probably experienced how painful it is to debug issues. Same way that ML is started to be used for medical diagnostics in e-health it can be also used to debug and find the root cause when there are problems. For example based on quality metrics from different participants and the status of the servers can diagnose if it is a bug or a network issue, and in the second case which network was the responsible.We can also use the classification algorithms available in ML to classify calls according to quality scores or other parameters to generate reports or monitoring purposes.
We can also use unsupervised learning to detect anomalies in the system automatically and trigger alerts.
You can follow me in Twitter if you are interested in Real Time Communications.


Thank you a lot for providing individuals with a very spectacular possibility to read critical reviews from this site.
ReplyDeletedigital training in chennai
Improving real-time communications with machine learning involves using various algorithms and models to enhance the quality, efficiency, and effectiveness of communication systems. Here’s a look at how machine learning can be applied to different aspects of real-time communications:
DeleteMachine Learning Projects for Final Year
1. Speech Recognition and Processing
Automatic Speech Recognition (ASR): Machine learning models can be trained to convert spoken language into text accurately in real time. This is crucial for applications such as voice assistants and real-time transcription services.
Deep Learning Projects for Final Year
Natural Language Processing (NLP)
Real-Time Translation: Machine learning models, such as neural machine translation (NMT) systems, can translate spoken or written text in real-time between different languages.
python projects for engineering students
This comment has been removed by the author.
ReplyDeleteThis post contains all about application of Artificial Intelligence In Speech Recognition. Thanks for the article.
ReplyDeleteExcellent blog post.
ReplyDeleteMachine Learning Training in Chennai
I can't match inside your head however if you happen to noticed me, that is the place I would be because of the photons reflecting off of me and into and thru your eye and on to your retina therefore transformed to electrical impulses which transmit as electrical indicators into your mind which reconstructs identical again right into a digital actuality model of me that now can match inside your cranium.This is great blog. If you want to know more about this visit here Machine Learning Model.
ReplyDeleteThanks For Sharing Excellent Blog. Machine Learning is steadily moving away from abstractions and engaging more in business problem solving with support from AI and Deep Learning. With Big Data making its way back to mainstream business activities, now smart (ML) algorithms can simply use massive loads of both static and dynamic data to continuously learn and improve for enhanced performance. Pridesys IT Ltd
ReplyDeleteKeep blogging.!!
ReplyDeletequite informative, thanks for sharing about new things here,
- Learn Digital Academy
Hmm, it seems like your site ate my first comment (it was extremely long) so I guess I’ll just sum it up what I had written and say, I’m thoroughly enjoying your blog.
ReplyDeletenebosh igc course in chennai
This comment has been removed by the author.
ReplyDeleteAwesome post. Thanks for sharing this post with us.to form a pc checkers application that was one amongst the primary programs that would learn from its own mistakes and improve its performance over time.Machine learning course one step any - it changes its program's behavior supported what it learns.
ReplyDeletethank you for giving such an great information.
ReplyDeletehttps://excelr.com.my/course/certification-on-industrial-revolution-4-0/
I’ve I’m a I’m planning to start my blog soon, but little lost on everything. Would you suggest starting with a free platform like Word Press or go for a paid option?
ReplyDeletenebosh course in chennai
offshore safety course in chennai
Amazing blog with the latest information. Your blog helps me to improve myself in many ways. Looking forward for more like this.
ReplyDeleteMachine Learning Training in Chennai
Machine Learning Training in Velachery
Data Science Course in Chennai
Data Science Certification in Chennai
Data Science Training in Tambaram
R Programming Training in Chennai
Machine Learning Training in Chennai
Machine Learning Course in Chennai
Great blog!!! This is a very different and unique content. I am waiting for your another post...
ReplyDeleteSocial Media Marketing Courses in Chennai
Social Media Marketing Training in Chennai
Oracle Training in Chennai
Tableau Training in Chennai
Pega Training in Chennai
Embedded System Course Chennai
Oracle DBA Training in Chennai
Social Media Marketing Courses in Chennai
Social Media Marketing Training in Chennai=
Thank you a lot for providing individuals with a very spectacular possibility to read critical reviews from this site.
ReplyDeletenebosh course in chennai
offshore safety course in chennai
It is going nice to go through your blog. Thank you for the information.
ReplyDeleteWeb Designing Course in Madurai
Web Designing Training in Madurai
Web Designing Course in Madurai
Web Designing Course in Coimbatore
Best Web Designing Institute in Coimbatore
Web Design Training in Coimbatore
Good job. This will useful for others who want to know more about technology. Useful one.
ReplyDeleteSpring Training in Chennai
Spring framework Training in Chennai
spring Training in Anna Nagar
Hibernate Training in Chennai
Hibernate course in Chennai
Struts Training in Chennai
Wordpress Training in Chennai
Spring Training in Chennai
This is really too useful and have more ideas and keep sharing many techniques. Eagerly waiting for your new blog keep doing more.
ReplyDeleteRPA Training in Chennai
R Training in Chennai
Automation Anywhere Training in Chennai
RPA Training in Porur
RPA Training in OMR
RPA Training in Adyar
RPA Training in Anna Nagar
Really a awesome blog for the freshers. Thanks for posting the information.
ReplyDeletecontent writing course in chennai
Blockchain Training in Chennai
Ionic Training in Chennai
IoT Training in Chennai
Xamarin Training in Chennai
Node JS Training in Chennai
German Classes in Anna Nagar
Spoken English Classes in Anna Nagar
content writing training in chennai
Such a great blog. I Got Lots of informations about this technology.Keep update like this....
ReplyDeleteTally Course in Chennai
Tally Course in Hyderabad
Tally training coimbatore
Tally Course in Coimbatore
Tally course in madurai
Tally Training in Chennai
Tally Institute in Chennai
Tally Classes in Bangalore
Best tally training institute in bangalore
Ethical hacking course in bangalore
Learned a lot of new things in this post. This post gives a piece of excellent information.
ReplyDeletePHP Training in Chennai
PHP Training in bangalore
PHP Training in Coimbatore
PHP Course in Madurai
PHP Course in Bangalore
PHP Training Institute in Bangalore
PHP Classes in Bangalore
Best PHP Training Institute in Bangalore
spoken english classes in bangalore
Data Science Courses in Bangalore
Nice Blog. Keep update more information about this..
ReplyDeleteIELTS Coaching in Chennai
IELTS coaching in bangalore
IELTS coaching centre in coimbatore
IELTS coaching in madurai
IELTS Coaching in Hyderabad
Best ielts coaching in bangalore
ielts training in bangalore
ielts coaching centre in bangalore
ielts classes in bangalore
ethical hacking course in bangalore
ReplyDeleteThe blog you shared is very good. I expect more information from you like this blog. Thankyou.
Python Training in bangalore
Python Course in Bangalore
Angularjs course Bangalore
Angularjs Training in Bangalore
Web Designing Course in bangalore
Web Development courses in bangalore
Salesforce Course in Bangalore
salesforce training in bangalore
Big Data Training in Bangalore
Hadoop Training in Bangalore
Great Job keep publishing such good articles, I would like to read more such articles going ahead.
ReplyDeletedata science training in aurangabad
data science course in aurangabad
ReplyDeleteIt's a very awesome article! Thanks a lot for sharing information.
Best Artificial Intelligence Training in Chennai
Artificial Intelligence Course in Chennai
Python Classes in Bangalore
Python Training Institute in Chennai
Python Course in Coimbatore
python training in hyderabad
ai training in bangalore
artificial intelligence course institute in bangalore
best artificial intelligence course in bangalor
salesforce course in bangalore
comparison
ReplyDeleteGood Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging…
ReplyDeleteDot Net Training in Chennai | Dot Net Training in anna nagar | Dot Net Training in omr | Dot Net Training in porur | Dot Net Training in tambaram | Dot Net Training in velachery
Glad to chat your blog,I seem to be forward to more reliable articles and i think we all wish to thank so many good articles,blog to share with us.
ReplyDeletelearn data scientist course
360digitmg best data science courses
This was not just great in fact this was really perfect your talent in writing was great.
ReplyDeletelearn360digitmg data science training
This comment has been removed by the author.
ReplyDeleteit's really cool blog. Linking is very useful thing.you have really helped
ReplyDelete360digitmg ai online course
it's really cool blog. Linking is very useful thing.you have really helped
ReplyDelete360digitmg ai online course
Such a very useful article. Very interesting to read this article.I would like to thank you for the efforts you had made for writing this awesome article.
ReplyDeleteData Science Online Training
Data Science Classes Online
Data Science Training Online
Online Data Science Course
Data Science Course Online
I recently came across your article and have been reading along. I want to express my admiration of your writing skill and ability to make readers read from the beginning to the end. I would like to read newer posts and to share my thoughts with you.
ReplyDeleteDevops training in bangalore
Devops class in bangalore
learn Devops in bangalore
places to learn Devops in bangalore
Devops schools in bangalore
Devops school reviews in bangalore
Devops training reviews in bangalore
Devops training in bangalore
Devops institutes in bangalore
Devops trainers in bangalore
learning Devops in bangalore
where to learn Devops in bangalore
best places to learn Devops in bangalore
top places to learn Devops in bangalore
Devops training in bangalore india
Wow it is really wonderful and awesome thus it is very much useful for me to understand many concepts and helped me a lot.
ReplyDeleteDigital Marketing certification Online Training in bangalore
Digital Marketing certification courses in bangalore
Digital Marketing certification classes in bangalore
Digital Marketing certification Online Training institute in bangalore
Digital Marketing certification course syllabus
best Digital Marketing certification Online Training
Digital Marketing certification Online Training centers
Your post is really awesome .it is very helpful for me to develop my skills in a right way
ReplyDeleteGerman Classes in Chennai | Certification | Language Learning Online Courses | GRE Coaching Classes in Chennai | Certification | Language Learning Online Courses | TOEFL Coaching in Chennai | Certification | Language Learning Online Courses | Spoken English Classes in Chennai | Certification | Communication Skills Training
This comment has been removed by the author.
ReplyDeleteIndustry reports are available through Federation of Indian Chambers of Commerce and Industry and Confederation of Indian Industry. artificial intelligence course in hyderabad
ReplyDeleteThis comment has been removed by the author.
ReplyDelete
ReplyDeletetrung tâm tư vấn du học canada vnsava
công ty tư vấn du học canada vnsava
trung tâm tư vấn du học canada vnsava uy tín
công ty tư vấn du học canada vnsava uy tín
trung tâm tư vấn du học canada vnsava tại tphcm
công ty tư vấn du học canada vnsava tại tphcm
điều kiện du học canada vnsava
chi phí du học canada vnsava
#vnsava
@vnsava
Really nice and interesting post. I was looking for this kind of information and enjoyed reading this one. Keep posting. Thanks for sharing.
ReplyDeletemachine learning course training in indore
I was looking for this certain information for a long time about "Real Time Communications Bits" . Thank you and good luck.
ReplyDeletedata science training in chennai
data science training in tambaram
android training in chennai
android training in tambaram
devops training in chennai
devops training in tambaram
artificial intelligence training in chennai
artificial intelligence training in tambaram
Amazing blog with the latest information. Your blog helps me to improve myself in many ways. Looking forward for more like this...
ReplyDeletejava training in chennai
java training in omr
aws training in chennai
aws training in omr
python training in chennai
python training in omr
selenium training in chennai
selenium training in omr
Hi it's really nice blog with new information,
ReplyDeleteThanks to share with us and keep more updates,
https://www.porurtraining.in/sap-training-course-in-chennai
https://www.porurtraining.in/microsoft-azure-training-in-porur-chennai
https://www.porurtraining.in/cyber-security-training-in-porur-chennai
https://www.porurtraining.in/ethical-hacking-training-in-porur-chennai
Great Job nice work...thanks for sharing this information..
ReplyDeleteangular js training in chennai
angular js training in annanagar
full stack training in chennai
full stack training in annanagar
php training in chennai
php training in annanagar
photoshop training in chennai
photoshop training in annanagar
This comment has been removed by the author.
ReplyDeleteGreat post! I am actually getting ready to across this information, It’s very helpful for this blog. Also great with all of the valuable information you have Keep up the good work you are doing well.
ReplyDeleteCRS Info Solutions Salesforce training for beginners
After completing all this tasks I got the skills to start looking to find a job as digital marketer! digital marketing training in hyderabad
ReplyDeleteReally very nice blog information.
ReplyDeleteacte reviews
acte velachery reviews
acte tambaram reviews
acte anna nagar reviews
acte porur reviews
acte omr reviews
acte chennai reviews
acte student reviews
Very good points you wrote here..Great stuff...I think you've made some truly interesting points.Keep up the good work.
ReplyDeleteabout us
Thanks for posting this info. I just want to let you know that I just check out your site and I find it very interesting and informative Rajasthan Budget Tours
ReplyDeleteVery nice blogs!!! i have to learning for lot of information for this sites…Sharing for wonderful information.Thanks for sharing this valuable information to our vision. You have posted a trust worthy blog keep sharing, data science online training
ReplyDeletePrimarily, data science refers to a field of study that uses the scientific approach to get an insight into the given data. The rapid growth in this field of science has resulted in the development of universities that have introduced different graduate programs related to data science. In this article, we are going to know more about both the fields. best course to learn artificial intelligence
ReplyDeleteReally impressed! Everything is very open and very clear clarification of issues. It contains truly facts. Your website is very valuable. Thanks for sharing.
ReplyDeletedata science course in Hyderabad
A person trained in Data Science has multiple options to choose from. He/she can work in a number of fields like Data Analytics, Software programmer, Machine learning engineer etc. And these options are going to grow by multiple folds in the coming future. data science course syllabus
ReplyDeleteIt will also check for any recently introduced new services or discounts that are finding enhanced interest among the customers. Salesforce training in Hyderabad
ReplyDeleteThanks For Sharing Excellent Blog. Machine Learning is steadily moving away from abstractions and engaging more in business problem solving with support from AI and Deep Learning.Digital Marketing Training in Chennai
ReplyDeleteDigital Marketing Training in Velachery
Digital Marketing Training in Tambaram
Digital Marketing Training in Porur
Digital Marketing Training in Omr
Digital Marketing Training in Annanagar
Excellent Blog! I would like to thank for the efforts you have made in writing this post. I am hoping the same best work from you in the future as well. I wanted to thank you for this websites! Thanks for sharing. Great websites!
ReplyDeletedata science course in India
I have bookmarked your website because this site contains valuable information in it. I am really happy with articles quality and presentation. Thanks a lot for keeping great stuff. I am very much thankful for this site.
ReplyDeletedata science training in Hyderabad
This comment has been removed by the author.
ReplyDeleteWow! Such an amazing and helpful post this is. I really really love it. It's so good and so awesome. I am just amazed. I hope that you continue to do your work like this in the future also.
ReplyDeleteArtificial Intelligence Course
Really, I appreciate your blog submission site List. Thank you for sharing your idea. keep sharing . I hope we get new updates related to blog and many other useful post.
ReplyDeleteBest SEO Company
Best digital marketing services India
top seo agency in India
leading digital marketing company Coimbatore
social media marketing services
SMM experts in India
SMM agencies Coimbatore
best social media marketing company
Best SEO Expert in USA
Best SEO Expert in gerogia
Best SEO Expert in texas
Best SEO Expert in california
Best SEO Expert in tennessee
Best SEO Expert in Virginia
Best SEO Expert in utah
Best SEO Expert in washinton
Best online reputation management experts in india
Top ORM agency
Best ORM company
Best SEO Expert in Coimbatore
leading seo agency in Coimbatore
SEO Coimbatore
SEO company in Coimbatore
SEO expert in Peelamedu
SEO expert in Gandhipuram
SEO expert in Tidal Park
SEO Expert in Saibaba Colony
SEO Expert in R S Puram
SEO expert in Vadavalli
SEO Expert in Perur
It is an excellent blog. Your post is very good and unique. I am eagerly waiting for your new post. Thanks for sharing and keep sharing more good blogs.
ReplyDeleteimpact of social media
applications of artificial intelligence in real world
advantages of php
rpa roles and responsibilities
php technical interview questions
php interview questions and answers for experienced
Thanks for Sharing This Article.It is very so much valuable content. I hope these Commenting lists will help to my website
ReplyDeletetop workday online training
Thanks for this wonderful blog .
ReplyDeletekeep sharing
mean Stack Development Training
dot net course
front end web development training in bangalore
Thank you for sharing this post.
ReplyDeleteData Science Online Training
Python Online Training
Thanks for sharing
ReplyDeletehttps://nareshit.com/salesforce-online-training/
Tech giants like Google along with Instagram have also made use of Python and its popularity continues to rise. Discussed below are some of the advantages offered by Python: data science course in india
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThanks for writhing this Real Time Communications improving with Machine Learning article. It is really true that this digitalize system of machine learning may help to run fast and develop the world. To know more about this system you can visit http://thetechnews.com/2020/09/10/ai-machine-learning-deep-learning-explained-in-5-minutes/
ReplyDeleteWow, wonderful content,
ReplyDeletehttps://www.techdatasolution.co.in/data-science-course-in-pune
ReplyDeleteThanks for sharing your views about the concept which you know much better. Its easy to read and understand by the way you wrote the blog contents.
machine learning course in chennai
Great information, nice to read your blog. Keep updating.
ReplyDeletepositive effects of social media
applications of artificial intelligence
ai applications
what is php used for in web design
rpa uipath jobs
salesforce interview questions for experienced
We are well established IT and outsourcing firm working in the market since 2013. We are providing training to the people ,
ReplyDeletelike- Web Design , Graphics Design , SEO, CPA Marketing & YouTube Marketing.Call us Now whatsapp: +(88) 01537587949
Digital marketing training
good post Mobile XPRESS
Free bangla sex video:Delivery Companies in UK
good post Mobile XPRESS
You have got done a good job along with your information that creates our work simple since you're giving such great data. Keep sharing this kind of information with us. web development service provider
ReplyDeletethanks for sharing blog
ReplyDeletekisson facility management
facility management companies in bangalore
Whatsapp Number Call us Now! 01537587949
ReplyDeleteplease visit us: Graphic Design Training
sex video: Dropped phone repair Erie
pone video usa: mobile phone repair in West Des Moines
pone video usa: Social Bookmarking Sites List 2021
I appreciate this article. it’s a very informative.
ReplyDeleteData Science Online Training
Python Online Training
Salesforce Online Training
Good job...! I am really happy to visit your post and thank you for your sharing...
ReplyDeleteReact JS Training in Chennai
Blue Prism Course in Bangalore
Blue Prism Training in Chennai
Blue Prism Online Training
Blue Prism Online Course
job guaranteed courses in bangalore
ReplyDeleteI had a nice experience on your website, thank you for sharing your knowledge and experience with us,
ReplyDeletebest regards
youtube
youtube
The TABE is for the most part not considered difficult, particularly on the off chance that a satisfactory sum of examining is included. What is the reason for the TABE test? The reason for the TABE is to decide what your abilities are in perusing, math, and English. Tabe applied math practice
ReplyDeletehttps://designingcourses.in/
ReplyDeleteVery Informative and useful... Keep it up the great work. I really appreciate your post.
graphic designing courses in Bangalore
web designing course in Bangalore
UX Design course in Bangalore
Of late, online IT training business is catching up world wide and Hyderabad is no exception. There are some major players in Hyderabad who have started their online training facilities couple of years ago. Salesforce Training in Hyderabad
ReplyDeleteThank you for a great and inspiring blog post. I just want you to know that I enjoyed reading your post. Duluth mn seo
ReplyDeleteI had the option to discover great data from your blog articles. best interiors
ReplyDeleteThanks for Sharing. Python Training in Chennai | Python Course in Chennai
ReplyDeletemotogp leather suits
ReplyDeleteIt's instructive and you are clearly entirely educated here. You have made me fully aware of differing sees on this point with fascinating and strong substance.
ReplyDeletedata scientist training in hyderabad
provides the quality service of customized fiber connections in the case of large businesses and government entities. Black Parade Jacket
ReplyDeleteWhile THC stays in your urine for between 2 and 10 days, it can stay for up to three months, even if you only smoke occasionally. This is because the drug metabolites in your blood spread across your body and stay there – including your hair. Most drug detox programs focus on your digestive system to eliminate THC, alcohol, and other toxins before they get absorbed by fat and stay in your body. However, if you smoke pot up to a week before your detox, there’s a good chance that the metabolites have already gotten to your scalp and are going to give the game away when you get tested. Even if it’s been a while since you last used weed, the lab will almost definitely detect traces of it in your system. Ultra Clean is a hair cleaner that may help with drug detoxification, including cannabis sativa Visit: https://www.urineworld.com/
ReplyDeleteNice blog, it is very impressive.
ReplyDeleteBig Data Course in Chennai
Big Data Training in Chennai
After reading your article I was struck by how knowledgeable you are about the topic at hand. You explained things in such a clear and concise way that it would be no surprise to see someone else feel the same way after reading your article.
ReplyDeleteArtificial Intelligence Training in Hyderabad
Artificial Intelligence Course in Hyderabad
Great information. Thank you for sharing with us.
ReplyDeleteRHCE Certification Training
ReplyDeletepoodle puppies for sale
sphynx kittens for sale
I tracked down your blog while looking for the updates, I am glad to be here. Exceptionally helpful substance and furthermore effectively reasonable giving…
ReplyDeleteData Science Training in Hyderabad
If you are looking IVR Service provider, it is also important to choose the right IVR Service provider for long-term growth. IVR Guru has been the leading IVR Service provider all over India. IVR Guru has been providing quality IVR Services with the best pricing. Check out the prices or call us at +91-9015350505
ReplyDeleteIncredible blog here! It's mind boggling posting with the checked and genuinely accommodating data. little joe cartwright jacket
ReplyDeleteEnable the DApp Browser On My iPhone
ReplyDeleteWrite An Out-of-Office Message
Permanently Delete My Kik Account
Hdhub4u Telugu movies download
ReplyDelete123mkv Bollywood movies download
Jiorockers free movie download
website to download Bollywood songs
active torrent websites
YTS AG Unblock from YTS Proxy
Tamilrockers Torrent
Ibomma download Telugu movies
HDHUB4U
Working Pirate bay Proxy
Really an awesome blog and very useful information for many people. Keep sharing more blogs again soon. Thank you.
ReplyDeleteAI Patasala Data Science Training in Hyderabad
En iyi oyun indirme sitesi olantorrent oyun sitemize herkesi bekleriz.
ReplyDeleteIt was not first article by this author as I always found him as a talented author. Spiderman Homecoming Peter Parker High School Jacket
ReplyDeleteİnsan böyle şeyler görünce mutlu oluyor
ReplyDeleteGood content and very informative blog.
ReplyDeleteLatest Breaking News
You should take help from professionals who have immense experience on Microsoft Business Central. They will help you with Solutions easily. Read: business central license types
ReplyDeleteweb designing is one of the best and top developing IT training course at this point. Learning web designing will help you to understand the concepts of HTML, CSS and JAVASCRIPT. After understanding all the concepts a web developer can be able to create his own website from scratch.
ReplyDeleteA2N Academy, one of the top-tier IT Skill Development Institutes in Bangalore, offers the best Web Designing course. Our skilled trainers recruited by the academy offer quality-based Web Designing Courses. Steadily, we guide our students to get placed in prominent web design companies through our online web designing course.
With a determined goal to nurture students for their skills and placement, we focus on developing web designing skills in students through our web designing course with a learning-by-doing approach and creating responsive websites from scratch for all platforms.
web designing course
keep up the good work. React JS Training in Chennai
ReplyDeleteIVR GURU Provides Virtual Phone Number, IVR Services, IVRS, Cloud Telephony, Voice Calls, Voice Survey Customer Lead Management, Toll Free Number, etc. For more info call us 9015350505
ReplyDeleteThis comment has been removed by the author.
ReplyDelete"If you are eager to enter the IT sector, you should try our career accelerated program to know more visit our website
ReplyDeletehttps://www.premiumlearnings.com/
To see our tutorials and success stores visit our Youtube page
https://www.youtube.com/c/PremiumLearningssystem "
Expressing thanks to you for partaking such immensities of information within few momentous sentences in this content. I am really looking forward to read some more motivating articles.
ReplyDeleteData Science training in Mumbai
Data Science course in Mumbai
SAP training in Mumbai
I loved to read this most informative blog, it's very interesting and different.
ReplyDeletechances of going to jail for reckless driving in virginia
Posibilidades de ir a la cárcel por conducción imprudente en Virginia
¿Puedes ir a la cárcel por conducir temerariamente en Virginia?
360DigiTMG is the top-rated institute for Data Science in Hyderabad and it has been awarded as the best training institute by Brand Icon. Click the link below to know about fee details.
ReplyDeletedata science course in hyderabad
Superb Blog with great information.
ReplyDeleteData science classes in Pune
Wonderful to you that you have shared this information with us. Read more info about. Star Trek Picard Field Jacket
ReplyDeleteSuperb blog.Thanks for sharing.
ReplyDeleteCCNA course in Pune
In fact, Artificial Intelligence & Machine Learning (AI / ML) plays big role in all sectors.
ReplyDeleteRegards,
BroadMind - IELTS coaching centre in Madurai
Integrated Risk Management is a comprehensive approach that organizations use to manage risks in a unified and coordinated manner across various departments, functions, and levels of the organization. IRM aims to break down silos and bring together different aspects of risk management, including financial, operational, compliance, strategic, and cyber risks, into a cohesive strategy. The goal is to create a holistic view of risks and opportunities, enabling more effective decision-making and resource allocation.
ReplyDeleteEnterprise Risk Management Software enables organizations to identify and assess risks across all areas of operation, including strategic, operational, financial, and compliance-related risks. This comprehensive view helps ensure that all potential risks are considered.
ReplyDeleteNice Post..
ReplyDeleteDigital Marketing Course in Warangal
What a great blog! I gained a lot of valuable information about this technology. Please keep posting updates like this.
ReplyDeletetally course in marathahalli
tally course in bangalore
tally course in nagawara
An excellent and innovative idea complemented by a variety of valuable and insightful content.
ReplyDeleteSAP ABAP Training in Hyderabad
Add a touch of vibrancy to your outfit with the Gap Pink Hoodie, available at Arsenaljackets.com. Soft, stylish, and perfect for any season, this hoodie is a must-have for your wardrobe. Stay cozy while turning heads in this trendy pink staple.
ReplyDeleteWith AI entering every imaginable industry possible it is important to utilize them for real time communications. It has become a must have skill for a digital marketer in 2025.
ReplyDeleteThe party poison jacket is everything a statement piece should be—bold, rebellious, and unapologetically loud. 💥🧥 With its electric blue base, red piping, and signature ray gun patch, it captures the chaotic, post-apocalyptic energy of the Danger Days universe perfectly. Gerard Way’s alter ego brought this look to life with so much attitude and creativity—it’s not just a jacket, it’s a symbol of survival and self-expression in true MCR fashion. Killjoys, make some noise! 🔫⚡🎸
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteVery Interesting! Please keep posting more!
ReplyDeleteIELTS Training in Chennai
This Aviator Black And White Shearling Jacket is everything! The bold color contrast gives it such a stylish, modern edge while still keeping that classic aviator vibe. The shearling lining looks super cozy and warm — perfect for colder months without sacrificing style. It’s definitely a statement piece that would elevate any outfit. Love it!
ReplyDeleteThis is a very informative article for Java learners who want to strengthen their practical development skills. Understanding theory is important, but real growth comes from working on live projects and real-world scenarios. Anyone aiming to become job-ready should definitely check Best Java Real Time Projects Online Training in Ameerpet to gain hands-on experience and understand how professional Java applications are developed and implemented.
ReplyDeleteSalesforce admin training delivers comprehensive expertise in managing and optimizing Salesforce environments. It explains automation rules and security controls clearly. This salesforce admin training strengthens configuration and troubleshooting skills. Learners work on live business cases. Project-based learning is included. Expert guidance is provided. It prepares industry-ready CRM administrators.
ReplyDeleteWell explained! training ui ux
ReplyDeleteenhances creativity and analytical skills, making products visually appealing and easy to use.
Step into bold street luxury with the camron pink coat , a statement piece designed for those who don’t follow trends they set them. Inspired by iconic hip-hop fashion energy, this coat brings a fearless pink aesthetic with a premium finish that turns every sidewalk into a runway. Perfect for standout winter styling with attitude.
ReplyDeleteThis blog post is very engaging and educational. The structure makes it easy for readers to follow. Thanks for sharing your expertise.service now admin course
ReplyDeleteGreat insights! Our OpenShift online training offers flexible, job-oriented learning with hands-on practice in Kubernetes, container orchestration, deployments, networking, security, CI/CD pipelines, and real-world projects to help learners build strong cloud and DevOps skills for career growth.openshift online training
ReplyDeleteGreat explanation! Infrastructure automation, monitoring, and deployment management are important skills for technology professionals. Practical implementation projects help learners gain hands-on experience through devops engineer course.
ReplyDeleteAdvance your professional journey with specialized training in Qlik Sense, Quantity Surveying, Quantum Engineering, R Tool, REST Assured, S/4 HANA SD, Salesforce, SAP BODS, SAP BW/4HANA, and SAP EWM in Singapore. These industry-oriented programs combine practical learning, real-time projects, and expert guidance to help learners gain in-demand skills and excel in technology, analytics, ERP, and enterprise management domains.
ReplyDeleteQlik Sense Training in Singapore
Quantity Surveying Training in Singapore
Quantum Engineering Training in Singapore
R Tool Training in Singapore
REST Assured Training in Singapore
S/4 HANA SD Training in Singapore
Salesforce Training in Singapore
SAP BODS Training in Singapore
SAP BW/4HANA Training in Singapore
SAP EWM Training in Singapore
Si buscas información sobre casinos que aceptan skrill, esta sección explica cómo funciona este método de pago dentro del casino online. Me parece interesante porque Skrill permite depósitos rápidos y seguros, sin necesidad de compartir datos bancarios directamente, lo que hace más cómoda y ágil la experiencia de juego para los usuarios en Chile y otros países.
ReplyDelete