Architecture for AI integration in conferencing applications
With the latest improvements in ML technology, especially generative algorithms and large language models, more and more conferencing applications are adding these capabilities to their offerings.
This ML technology can be applied to conferencing applications at two different levels: the infrastructure level with improvements in media handling and transmission, and the application level with new features or capabilities for the users.
At the infrastructure level (codecs, noise suppression, etc.) most of the high-level ideas were covered in this other post. Some interesting recent advances are applying “ML codecs” for audio redundancy, and the next frontier is applying generative algorithms also to video, as well as general applications to photorealistic avatars.
This post focuses on the second level (the application part) and how to implement typical features such as summarization, image generation, or moderation. The idea here is to present a reference architecture that can be used to implement these services.
The architecture presented below is based on two core ideas:
1. The system is split into three different subsystems that have different execution patterns:
- One on-demand subsystem that the application can use to request specific capabilities when needed.
- One offline subsystem that processes files, events and recordings in the background for enhancement, filtering, or extracting relevant information. This system has a tradicional storage bucket as backend (f.e. AWS S3).
- One online subsystem that processes all communication events (messaging, signaling, messaging) in almost real-time to make decisions, extract information, or enhance those events. This system has a streaming queue as backend (f.e Apache Kafka).
2. All the ML algorithms are exposed behind an API/Gateway to abstract details of the implementation and interface with hosted models and external providers.
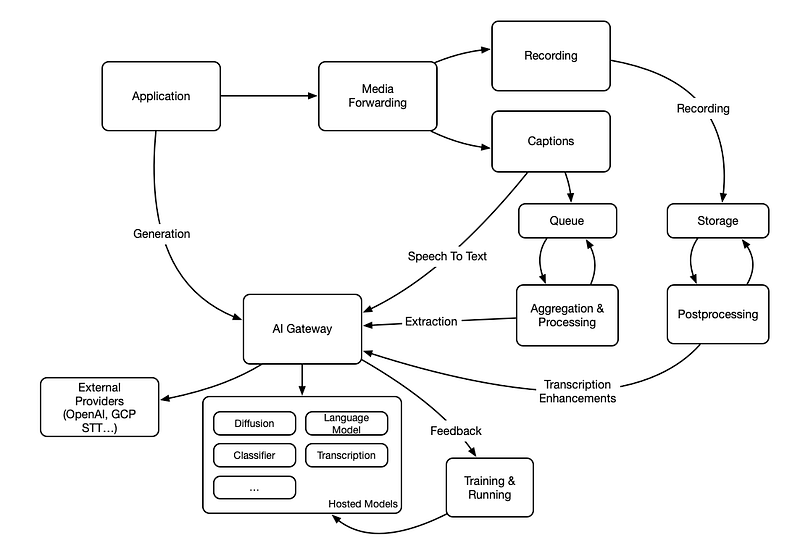
With that architecture these are some typical features and how they could be implemented:
- Media generation (images, music, memes…) can be requested from the application when requested by the user or automatically when needed by the application.
- Enhanced recordings, for example with the typical super-resolution algorithms, can be generated by a background post-processing process ran every time there is a new recording generated in the storage bucket.
- Real time extraction of relevant fields from the conversation (f.e. action items) can be implemented with a process reading the captions from the queue, grouping them in chunks by topic or speaker, and then sending those chunks to the AI Gateway. That information can be fed back to the queue so that other processes or the application can make use of them.
This post express my personal views. Feedback is more than welcomed either here or in Twitter.



Power BI live training focuses on real-time instruction and practical dashboard creation techniques. It explains report publishing and sharing clearly. This power bi live training enhances technical reporting and analytics skills. Learners gain live project experience. Performance optimization methods are included. Expert support is provided. It prepares skilled BI developers.
ReplyDeleteNice insights! Learning devops and aws training
ReplyDeletebridges development and operations, enabling continuous integration and faster releases.